http headers
头部字段
General1
2
3
4
5Request URL:http://www.cnblogs.com/sunny-sl/p/6529830.html
Request Method:GET
Status Code:200 OK
Remote Address:42.121.252.58:80
Referrer Policy:origin
Response Headers1
2
3
4
5
6
7
8
9
10
11Cache-Control:private, max-age=10
Connection:keep-alive
Content-Encoding:gzip
Content-Type:text/html; charset=utf-8
Date:Fri, 09 Feb 2018 00:35:07 GMT
Expires:Fri, 09 Feb 2018 00:35:17 GMT
Last-Modified:Fri, 09 Feb 2018 00:35:07 GMT
Transfer-Encoding:chunked
Vary:Accept-Encoding
X-Frame-Options:SAMEORIGIN
X-UA-Compatible:IE=10
Request Headers1
2
3
4
5
6
7
8
9
10
11Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.9,de;q=0.8,en;q=0.7
Cache-Control:max-age=0
Connection:keep-alive
Cookie:Hm_lvt_cc17b07fc9529e3d80b4482c9ce09086=1503727633; __utma=226521935.1803516701.1504280386.1504280386.1504280386.1; __utmz=226521935.1504280386.1.1.utmccn=(referral)|utmcsr=google.com.au|utmcct=/|utmcmd=referral; pgv_pvi=3195154432;
Host:www.cnblogs.com
If-Modified-Since:Fri, 09 Feb 2018 00:23:55 GMT
Referer:https://www.google.com/
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36
Accept的含义
如
Accept: application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5表示的含义是什么?
application / xml , application / xhtml + xml和image / png是首选媒体类型,但如果它们不存在,则发送文本/ html实体( text/html;q=0.9 ),如果不存在,则发送文本/普通实体( text/plain;q=0.8 ),如果不存在,则发送具有任何其他媒体类型( /;q=0.5 )
常见的Content-type(mime)类型
- text/html
- application/xml
- application/json
- application/x-www-form-urlencoded 最常见的 POST 提交数据的方式了。浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded方式提交数据。 传递的key/val会经过URL转码,所以如果传递的参数存在中文或者特殊字符需要注意
- multipart/form-data 使用表单上传文件时,必须让 form 的 enctyped 等于这个值
- text/plain
- image/png
keep-alive模式
HTTP的短连接&长连接
- 短连接:每次请求一个资源就建立连接,请求完成后连接立马关闭。每次请求都经过“创建tcp连接->请求资源->响应资源->释放连接”这样的过程
- 长连接(persistent connection):只建立一次连接,多次资源请求都复用该连接,完成后关闭。要请求一个页面上的十张图,只需要建立一次tcp连接,然后依次请求十张图,等待资源响应,释放连接
- 并行连接(multiple connections),其实就是并发的短连接
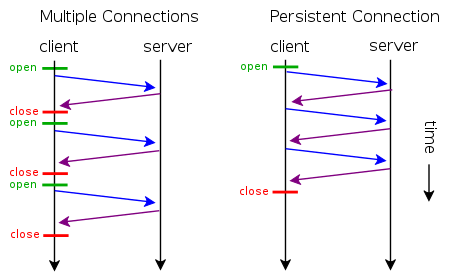
client和server keep-alive模式访问流程
- client发出的HTTP请求头需要增加Connection:keep-alive字段
- Web-Server端要能识别Connection:keep-alive字段,并且在http的response里指定Connection:keep-alive字段,告诉client,我能提供keep-alive服务,并且”应允”client我暂时不会关闭socket连接
注意:
- 在HTTP/1.0里,为了实现client到web-server能支持长连接,必须在HTTP请求头里显示指定
Connection:keep-alive - 在HTTP/1.1里,就默认是开启了keep-alive,要关闭keep-alive需要在HTTP请求头里显示指定
Connection:close
####
Keep-Alive选项
用法:Keep-Alive: name[=value][, name=[value]]…
完全可选,但只有在包含了Connection: Keep-Alive首部的情况下才可使用它。参数timeout:在Keep-Alive响应首部中发送,告诉客户端服务器估计会在打开状态保持到连接空闲多长时间后关闭连接。
- 参数max:在Keep-Alive响应首部中发送,告诉客户端服务器还会为另外几个http事务将连接保持在打开状态。
注意,这两个参数值仅仅是估计,并非承诺。
例如:1
2Connection: Keep-Alive
Keep-Alive: max=5, timeout=120
说明服务器最多还会为另外5个事务保持连接在打开状态,或者将打开状态保持到连接空闲了2两分钟后关闭。
参考:
缓存

http code与缓存层
- 200状态:当浏览器本地没有缓存或下一层失效时或用户点击CTRL+F5,直接去服务器下载最新数据
- 304状态:这一层由last-modify/etag控制。当下一层失效或用户点击F5时,浏览器会发送请求给服务器,如果服务端没有变化,则返回304给浏览器
- 200(from cache):这一层由expires/cache-control控制。
1. expires(http1.0版有效)是绝对时间。
2. cache-control(http1.1版本有效),相对时间,两者都存在时,cache-control覆盖expires只要没有失效,浏览器只访问自己的缓存Last-Modified
在浏览器第一次请求某一个URL时,服务器端的返回状态会是200,内容是你请求的资源,同时有一个Last-Modified的属性标记(HttpReponse Header)此文件在服务期端最后被修改的时间,格式类似这样:Last-Modified:Tue, 24 Feb 2009 08:01:04 GMT
客户端第二次请求此URL时,根据HTTP协议的规定,浏览器会向服务器传送If-Modified-Since报头(HttpRequest Header),询问该时间之后文件是否有被修改过:
If-Modified-Since:Tue, 24 Feb 2009 08:01:04 GMT
如果服务器端的资源没有变化,则自动返回HTTP304(NotChanged.)状态码,内容为空,这样就节省了传输数据量。当服务器端代码发生改变或者重启服务器时,则重新发出资源,返回和第一次请求时类似。从而保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。
注:如果If-Modified-Since的时间比服务器当前时间(当前的请求时间request_time)还晚,会认为是个非法请求
Etag工作原理
HTTP协议规格说明定义ETag为“被请求变量的实体标记”(参见14.19)。简单点即服务器响应时给请求URL标记,并在HTTP响应头中将其传送到客户端,类似服务器端返回的格式:Etag:“5d8c72a5edda8d6a:3239″
客户端的查询更新格式是这样的:If-None-Match:“5d8c72a5edda8d6a:3239″
如果ETag没改变,则返回状态304。
Expires
给出的日期/时间后,被响应认为是过时。如Expires:Thu, 02 Apr 2009 05:14:08 GMT
需和Last-Modified结合使用。用于控制请求文件的有效时间,当请求数据在有效期内时客户端浏览器从缓存请求数据而不是服务器端.当缓存中数据失效或过期,才决定从服务器更新数据。
Last-Modified和Expires
Last-Modified标识能够节省一点带宽,但是还是逃不掉发一个HTTP请求出去,而且要和Expires一起用。而Expires标识却使得浏览器干脆连HTTP请求都不用发,比如当用户F5或者点击Refresh按钮的时候就算对于有Expires的URI,一样也会发一个HTTP请求出去,所以,Last-Modified还是要用的,而且要和Expires一起用。
Etag和Expires
如果服务器端同时设置了Etag和Expires时,Etag原理同样,即与Last-Modified/Etag对应的HttpRequestHeader:If-Modified-Since和If-None-Match。我们可以看到这两个Header的值和WebServer发出的Last-Modified,Etag值完全一样;在完全匹配If-Modified-Since和If-None-Match即检查完修改时间和Etag之后,服务器才能返回304.
Last-Modified和Etag
分布式系统里多台机器间文件的last-modified必须保持一致,以免负载均衡到不同机器导致比对失败
分布式系统尽量关闭掉Etag(每台机器生成的etag都会不一样)
Last-Modified和ETags请求的http报头一起使用,服务器首先产生Last-Modified/Etag标记,服务器可在稍后使用它来判断页面是否已经被修改,来决定文件是否继续缓存
过程如下:
1.客户端请求一个页面(A)。
2.服务器返回页面A,并在给A加上一个Last-Modified/ETag。
3.客户端展现该页面,并将页面连同Last-Modified/ETag一起缓存。
4.客户再次请求页面A,并将上次请求时服务器返回的Last-Modified/ETag一起传递给服务器。
5.服务器检查该Last-Modified或ETag,并判断出该页面自上次客户端请求之后还未被修改,直接返回响应304和一个空的响应体。
注:
1、Last-Modified和Etag头都是由WebServer发出的HttpReponse Header,WebServer应该同时支持这两种头。
2、WebServer发送完Last-Modified/Etag头给客户端后,客户端会缓存这些头;
3、客户端再次发起相同页面的请求时,将分别发送与Last-Modified/Etag对应的HttpRequestHeader:If-Modified-Since和If-None-Match。我们可以看到这两个Header的值和WebServer发出的Last-Modified,Etag值完全一样;
4、通过上述值到服务器端检查,判断文件是否继续缓存;
关于 Cache-Control: max-age=秒 和 Expires
Expires = 时间,HTTP 1.0 版本,缓存的截止时间,允许客户端在这个时间之前不去检查(发请求)
max-age = 秒,HTTP 1.1版本,资源在本地缓存多少秒。
如果max-age和Expires同时存在,则被Cache-Control的max-age覆盖。
Expires 的一个缺点就是,返回的到期时间是服务器端的时间,这样存在一个问题,如果客户端的时间与服务器的时间相差很大,那么误差就很大,所以在HTTP 1.1版开始,使用Cache-Control: max-age=秒替代。
Expires =max-age + “每次下载时的当前的request时间”
所以一旦重新下载的页面后,expires就重新计算一次,但last-modified不会变化
http/2.0与http/1.1区别
1.什么是HTTP/2
HTTP/2(超文本传输协议第2版,最初命名为HTTP 2.0),是HTTP协议的的第二个主要版本,使用于万维网。HTTP/2是HTTP协议自1999年HTTP 1.1发布后的首个更新,主要基于SPDY协议。
2.与HTTP/1相比,主要区别包括
- HTTP/2采用二进制格式而非文本格式
- HTTP/2是完全多路复用的,而非有序并阻塞的——只需一个连接即可实现并行
- 使用报头压缩,HTTP/2降低了开销
- HTTP/2让服务器可以将响应主动“推送”到客户端缓存中
HTTP/2为什么是二进制?
比起像HTTP/1.x这样的文本协议,二进制协议解析起来更高效、“线上”更紧凑,更重要的是错误更少。
为什么 HTTP/2 需要多路传输?
HTTP/1.x 有个问题叫线端阻塞(head-of-line blocking), 它是指一个连接(connection)一次只提交一个请求的效率比较高, 多了就会变慢。 HTTP/1.1 试过用流水线(pipelining)来解决这个问题, 但是效果并不理想(数据量较大或者速度较慢的响应, 会阻碍排在他后面的请求). 此外, 由于网络媒介(intermediary )和服务器不能很好的支持流水线, 导致部署起来困难重重。
而多路传输(Multiplexing)能很好的解决这些问题, 因为它能同时处理多个消息的请求和响应; 甚至可以在传输过程中将一个消息跟另外一个掺杂在一起。
所以客户端只需要一个连接就能加载一个页面。
消息头为什么需要压缩?
假定一个页面有80个资源需要加载(这个数量对于今天的Web而言还是挺保守的), 而每一次请求都有1400字节的消息头(着同样也并不少见,因为Cookie和引用等东西的存在), 至少要7到8个来回去“在线”获得这些消息头。这还不包括响应时间——那只是从客户端那里获取到它们所花的时间而已。
这全都由于TCP的慢启动机制,它会基于对已知有多少个包,来确定还要来回去获取哪些包 – 这很明显的限制了最初的几个来回可以发送的数据包的数量。
相比之下,即使是头部轻微的压缩也可以是让那些请求只需一个来回就能搞定——有时候甚至一个包就可以了。
这种开销是可以被节省下来的,特别是当你考虑移动客户端应用的时候,即使是良好条件下,一般也会看到几百毫秒的来回延迟。
服务器推送的好处是什么?
当浏览器请求一个网页时,服务器将会发回HTML,在服务器开始发送JavaScript、图片和CSS前,服务器需要等待浏览器解析HTML和发送所有内嵌资源的请求。
服务器推送服务通过“推送”那些它认为客户端将会需要的内容到客户端的缓存中,以此来避免往返的延迟。