数据库三大范式
1. 第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式
第一范式需要按照系统的实际需求来定。比如一般”地址”这个属性都是一个字段就可以了,但是如果系统经常访问城市,那就可以对地址进行拆分,
这样在对地址进行查询的时候就比较的方便。
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能
2. 第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中
如图:订单信息表:一个订单中可能有多个商品,所以将订单号和商品编号作为联合主键。
上图中商品名称、单位、价格只与商品有关于订单号无关,所以是不满足第二范式的。这时候应该把商品信息拆分为单独的表,如下:
3. 第三范式(确保每列都和主键列直接相关,而不是间接相关)
满足第三范式(3NF)必须先满足第二范式(2NF)。第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息
参考
mysql创建索引原则
- 较频繁的作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合创建索引
- 不会出现在WHERE子句中的字段不该创建索引
数据库优化的思路
1. SQL语句优化
- 避免select *
- 字段尽可能的使用 NOT NULL
- 尽量避免在 !=或<>和not in操作符,避免全表扫描
- where 及 order by 涉及的列上建立索引
- 尽量少使用join查询
2. 索引优化
合理增加索引,查看 mysql创建索引原则
3. 数据库结构优化
- 范式优化:消除冗余(节省空间)
- 反范式优化:比如适当加冗余等(减少join)
- 表的垂直拆分和水平拆分
4. 服务器硬件优化
- 提升服务器硬件配置
5. 缓存机制
- 添加缓存机制,使用(redis,memcache)
- 不经常改动的使用静态页面
表的垂直拆分和水平拆分
垂直拆分
垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表
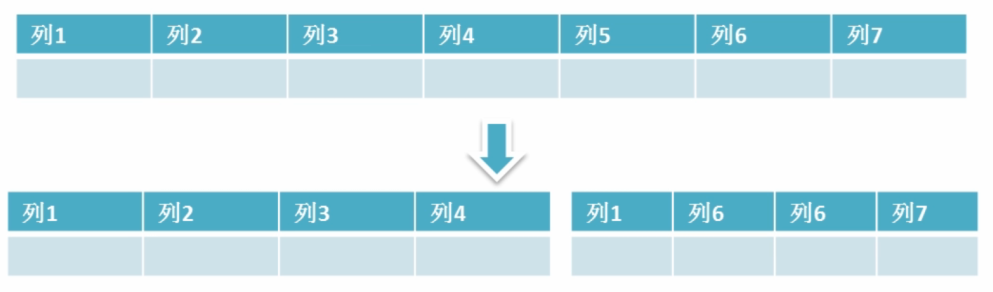
原则
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 经常组合查询的列放在一张表中;
ps:
垂直拆分更多时候就应该在数据表设计之初就执行的步骤,然后查询的时候用jion关键起来即可;
水平拆分
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放.
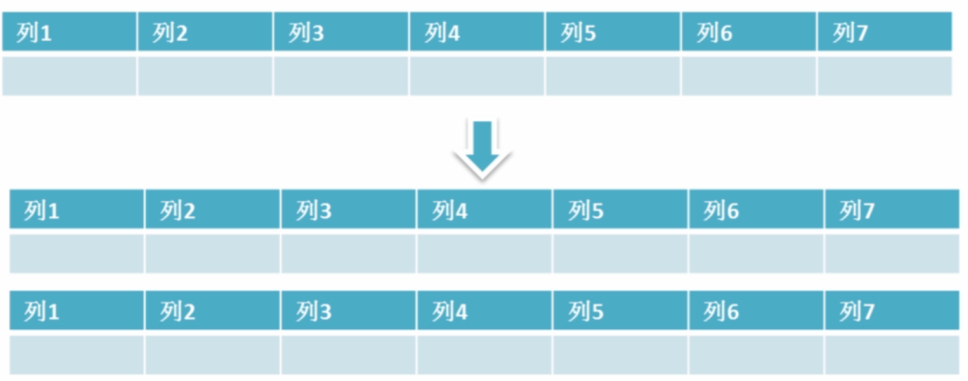
拆分原则
通常使用取模的方式来进行表的拆分
应用
比如一张有400W的用户表users,为提高其查询效率我们把其分成4张表users1,users2,users3,users4
通过用ID取模的方法把数据分散到四张表内Id%4+1 = [1,2,3,4]
插入:在insert时还需要一张临时表uid_temp来提供自增的ID,该表的唯一用处就是提供自增的ID;得到自增的ID后,又通过取模法进行分表插入
然后查询,更新,删除也是通过取模的方法来查询1
2
3
4$_GET['id'] = 17,
17%4 + 1 = 2,
$tableName = 'users'.'2'
Select * from users2 where id = 17;
注意:进行水平拆分后的表,字段的列和类型和原表应该是相同的,但是要记得去掉auto_increment自增长
mysql CPU告警解决思路
- top 之后,确实是mysqld进程占据了所有资源
- 查看error日志,无任何异常
- show engine innodb status\G,没有死锁信息
- show full processlist:没有耗时非常大的慢sql再跑。看并发,当前的线程总数量也才30个左右
- 查看iostat,读写正常
- 查看slow log:然后优化sql
drop,delete与truncate的区别
- delete和truncate只删除表的数据不删除表的结构, trucate删除表数据自增id从1开始,delete删除可加where语句
- 速度,一般来说: drop> truncate >delete
- delete语句是dml,这个操作会放到rollback中,事务提交之后才生效;如果有相应的trigger,执行的时候将被触发.
- truncate,drop是ddl, 操作立即生效,原数据不放到rollback segment中,不能回滚. 操作不触发trigger.
数据库事务的四个特性及含义
数据库事务transanction正确执行的四个基本要素。ACID,原子性(Atomicity)、一致性(Correspondence)、隔离性(Isolation)、持久性(Durability)。
- 原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
- 隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。
- 持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚
查找慢SQL查询
开启慢查询配置
slow_query_log
这个参数设置为ON,可以捕获执行时间超过一定数值的SQL语句。
long_query_time
当SQL语句执行时间超过此数值时,就会被记录到日志中,建议设置为1或者更短。
slow_query_log_file
记录日志的文件名
log_queries_not_using_indexes
这个参数设置为ON,可以捕获到所有未使用索引的SQL语句,尽管这个SQL语句有可能执行得挺快。
检测执行效率
1. 查看慢查询日志
查看slow_query_log_file配置的文件
2. show processlist 命令
SHOW PROCESSLIST显示哪些线程正在运行
各列的含义和用途
ID列:一个标识,你要kill一个语句的时候很有用,用命令杀掉此查询 mysqladmin kill 进程号。
user列:显示单前用户,如果不是root,这个命令就只显示你权限范围内的sql语句。
host列:显示这个语句是从哪个ip的哪个端口上发出的。用于追踪出问题语句的用户。
db列:显示这个进程目前连接的是哪个数据库。
command列:显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)。
time列:此这个状态持续的时间,单位是秒。
state列:显示使用当前连接的sql语句的状态,很重要的列,后续会有所有的状态的描述,请注意,state只是语句执行中的某一个状态,一个 sql语句,以查询为例,可能需要经过copying to tmp table,Sorting result,Sending data等状态才可以完成
info列:显示这个sql语句,因为长度有限,所以长的sql语句就显示不全,但是一个判断问题语句的重要依据
3. explain来了解SQL执行的状态
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句
3.1 用法
在select语句前加上explain就可以了
例如:
1 | explain select * from info where uid = 1234 order by id desc limit 1\G; |
运行结果:
1 | id: 1 |
3.2 列含义
table: 显示这一行的数据是关于哪张表的
select_type: 表示 SELECT 的 类型,常见的取值有 SIMPLE (简单表,即不使用表连接或者子查询)、 PRIMARY (主查询,即外层的查询)、 UNION ( UNION 中的第二个或者后面的查询语句)、 SUBQUERY (子查询中的第一个 SELECT )等
type : 这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL
表示表的连接类型,性能由好到差的连接类型为 system (表中仅有一行,即常量表)、 const (单表中最多有一个匹配行,例如 primary key 或者 unique index )、 eq_ref (对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用 primary key 或者 unique index )、 ref (与 eq_ref 类似,区别在于不是使用 primary key 或者 unique index ,而是使用普通的索引)、 ref_or_null ( 与 ref 类似,区别在于条件中包含对 NULL 的查询 ) 、 index_merge ( 索引合并优化 ) 、 unique_subquery ( in 的后面是一个查询主键字段的子查询)、 index_subquery ( 与 unique_subquery 类似,区别在于 in 的后面是查询非唯一索引字段的子查询)、 range (单表中的范围查询)、 index (对于前面的每一行,都通过查询索引来得到数据)、 all (对于前面的每一行,都通过全表扫描来得到数据)
possible_keys: 显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句 中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len: 使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref: 显示索引的哪一列被使用了,如果可能的话,是一个常数
rows: MYSQL认为必须检查的用来返回请求数据的行数
extra: 执行情况的说明和描述
参考:
mysql 数据类型
1、整型
| MySQL数据类型 | 含义(有符号) |
|---|---|
| tinyint(m) | 1个字节 范围(-128~127) |
| smallint(m) | 2个字节 范围(-32768~32767) |
| mediumint(m) | 3个字节 范围(-8388608~8388607) |
| int(m) | 4个字节 范围(-2147483648~2147483647) |
| bigint(m) | 8个字节 范围(+-9.22*10的18次方) |
取值范围如果加了unsigned,则最大值翻倍,如tinyint unsigned的取值范围为(0~255)。
int(m)里的m是表示SELECT查询结果集中的显示宽度,并不影响实际的取值范围,没有影响到显示的宽度,不知道这个m有什么用。
2、浮点型(float和double)
| MySQL数据类型 | 含义 |
|---|---|
| float(m,d) | 单精度浮点型 8位精度(4字节) m总个数,d小数位 |
| double(m,d) | 双精度浮点型 16位精度(8字节) m总个数,d小数位 |
设一个字段定义为float(5,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位。
3、定点数
浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值。
decimal(m,d) 参数m<65 是总个数,d<30且 d<m 是小数位。
4、字符串(char,varchar,_text)
| MySQL数据类型 | 含义 |
|---|---|
| char(n) | 固定长度,最多255个字符 |
| varchar(n) | 固定长度,最多65535个字符 |
| tinytext | 可变长度,最多255个字符 |
| text | 可变长度,最多65535个字符 |
| mediumtext | 可变长度,最多2的24次方-1个字符 |
| longtext | 可变长度,最多2的32次方-1个字符 |
char和varchar:
1.char(n) 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉。所以char类型存储的字符串末尾不能有空格,varchar不限于此。
2.char(n) 固定长度,char(4)不管是存入几个字符,都将占用4个字节,varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),所以varchar(4),存入3个字符将占用4个字节。
3.char类型的字符串检索速度要比varchar类型的快。
varchar和text:
1.varchar可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),text是实际字符数+2个字节。
2.text类型不能有默认值。
3.varchar可直接创建索引,text创建索引要指定前多少个字符。varchar查询速度快于text,在都创建索引的情况下,text的索引似乎不起作用。
5.二进制数据(_Blob)
1._BLOB和_text存储方式不同,_TEXT以文本方式存储,英文存储区分大小写,而_Blob是以二进制方式存储,不分大小写。
2._BLOB存储的数据只能整体读出。
3._TEXT可以指定字符集,_BLO不用指定字符集。
6.日期时间类型
| MySQL数据类型 | 含义 |
|---|---|
| date | 日期 ‘2008-12-2’ |
| time | 时间 ‘12:25:36’ |
| datetime | 日期时间 ‘2008-12-2 22:06:44’ |
| timestamp | 自动存储记录修改时间 |
若定义一个字段为timestamp,这个字段里的时间数据会随其他字段修改的时候自动刷新,所以这个数据类型的字段可以存放这条记录最后被修改的时间。
数据类型的属性
| MySQL关键字 | 含义 |
|---|---|
| NULL | 数据列可包含NULL值 |
| NOT NULL | 数据列不允许包含NULL值 |
| DEFAULT | 默认值 |
| PRIMARY KEY | 主键 |
| AUTO_INCREMENT | 自动递增,适用于整数类型 |
| UNSIGNED | 无符号 |
| CHARACTER SET name | 指定一个字符集 |